通过selenium、chromedriver等python脚本迁移下载51cto博文并转换成本地html和markdown格式页面
1.动机说明
由于早些年写博客,国内比较流行的有51cto、csdn等,最早我也是2007年注册使用了51cto,发表了约108篇,51cto几次改版,除了文章关键字会脱敏处理, 还有丢失过博文,广告也多;因此决定将以往的博客迁移至github上,通过pages檲 ,可以直接访问,非常方便,只要简单配置,应用模板,以markdown格式存入就可以访问博文;不要太方便,另外主要是可控度大;而且可以和github代码库紧密结合。哪还说啥;说干就干;
2.思路与问题
思路一:迁移老博文主要是后台导出, 再导入github;于是登录51cto后台,发现没有直接导出功能,有一个针对单博文在编辑状态下导出,不过只能导到.wk的格式;最终发现不能兼容markdown格式;也就是说没办法通过51cto后台导出markdown格式的博文,哪只能换思路了
思路二:通过爬虫技术将自己的老博文全爬下来,再转换成markdown格式上传到github中不就行了;因此测试了一把,发现用常用的爬虫技术没效(requestst 和 BeautifulSoup模块)代码如下:
import requests
from bs4 import BeautifulSoup
# 初始化session
session = requests.Session()
# 目标URL
url = 'https://blog.51cto.com/dyc2005'
# 发送初始请求
response = session.get(url)
response.encoding = 'utf-8'
print(response.text)
# 检查请求是否成功
if response.status_code == 200:
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取JavaScript中的参数
script_tag = soup.find('script')
if script_tag:
# 这里假设参数在script标签内,具体提取逻辑可能需要根据实际情况调整
script_content = script_tag.string
arg1 = 'E2D266E77DF32154CBA1F5D0084BA1216F638E22' # 根据提供的代码,假设参数是这个
# 设置cookie
session.cookies.set("acw_sc__v2", arg1)
# 重新发送请求
response = session.get(url)
response.encoding = 'utf-8'
if response.status_code == 200:
# 解析新的HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.find_all('a', class_='tit')
for article in articles:
title = article.get_text()
link = article['href']
print(f'Title: {title}')
print(f'Link: {link}')
print('-' * 40)
else:
print(f'Failed to retrieve the webpage after setting cookie. Status code: {response.status_code}')
else:
print('No script tag found.')
else:
print(f'Failed to retrieve the initial webpage. Status code: {response.status_code}')
爬下来是内容是一些看不太懂的javascripts脚本,应该是做了反爬处理;如下:
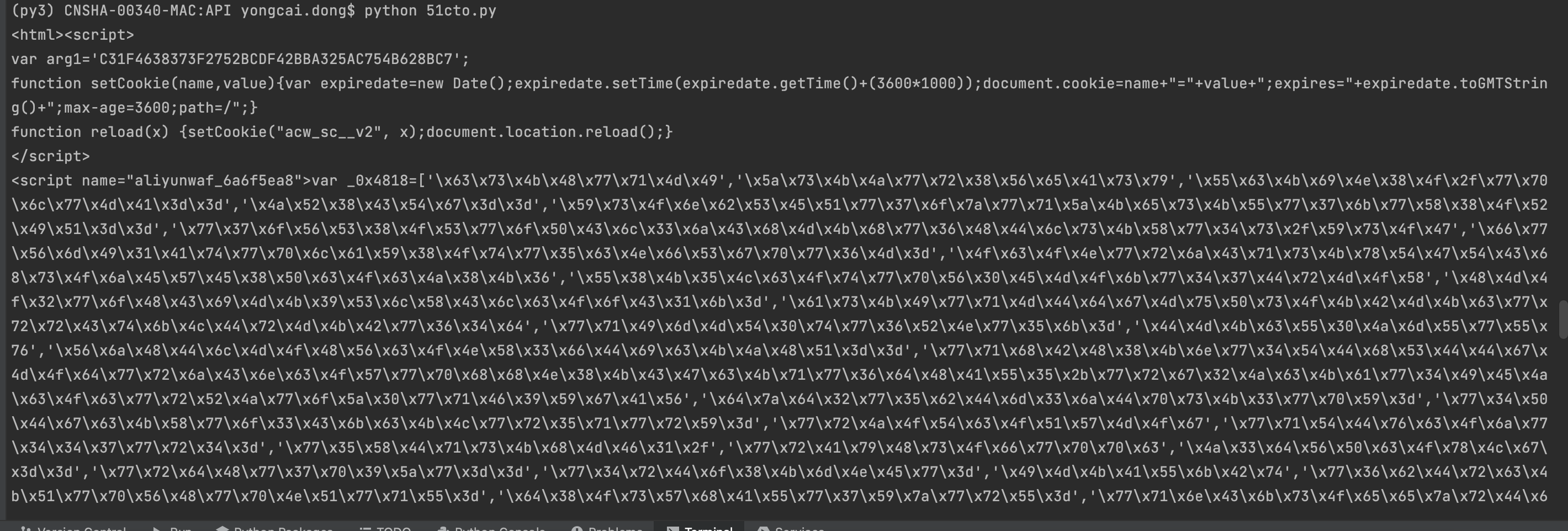
思路三:印象中还有一种方法使用selenium模块结合chrome浏览器驱动,模拟测试下载页面(所有博文页面)到本地,再转换成markdown;说试就试,反正生命在于折腾,试试也不要钱;
具体流程如下:
0). 配置测试环境,下载 ChromeDriver (需要和你电脑上chrome版本匹配)并放到指定目录下;
1). 先进行主页面获取,确保主机保存在本地为正常的html格式;而非上面不可识别的格式
2). 对主页面进行本地分析并将将包含的分布内容保存到本地,如主页.html、2.html等
3). 将主页和所有分页中博文url和标题写入文件
4). 对保存的url和标题文件进行页面内容获取,并保存在指定目录下(最终获取所有博文本地html文件)
5). 将本地html文件进行转换成markdown格式,将带水印的图片下载到本地去水印;完成本地markdown格式的访问
这步中自动转换不彻底,需要将不必要的内容手动删除;稍微有点烦,但好歹已经节省了大部分工作了
6). 将markdown格式上传到github指定目录中;完成迁移
3.测试代码
以下的测试在mac电脑上,都基于python 3.8;需要用到的python模块如下
pip install selenium beautifulsoup4 markdownify
代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
import re
import os
from bs4 import BeautifulSoup
# 配置Chrome浏览器选项
chrome_options = Options()
chrome_options.add_argument("--headless") # 启用无头模式
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--window-size=1920x1080")
# 替换为你的ChromeDriver路径
chromedriver_path = '/Users/API/chromedriver'
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)
def create_driver():
# 创建Chrome浏览器驱动
try:
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)
return driver
....... 以下部分省略 ......
if __name__ == '__main__':
page_urls_file = 'PageUrls.txt'
url = 'https://blog.51cto.com/xxxx' # xxxx是你的博客账号或后缀
pages_pattern = re.compile(r'https://blog\.51cto\.com/xxxxx/p_\d+')
article_pattern = re.compile(r'https://blog\.51cto\.com/xxxxx/\d+')
# 保存主页的HTML内容
save_main_page(url, 'main.html')
# 获取所有分页的URL列表(含首页)
url_list = get_pages_url('blogs/main.html', pages_pattern, url)
print(url_list)
for url_info in url_list:
savefile = url_info["title"] + '.html'
# print(url_info["url"], savefile)
get_pages(url_info["url"], savefile)
page_urls = get_urls(f"blogs/{savefile}")
save_file(page_urls_file, page_urls)
# 通过PageUrls.txt中的url列表获取文章内容保存为标题.html文件
with open(f"blogs/{page_urls_file}", 'r', encoding='utf-8') as file:
html_content = file.readlines()
for link in html_content:
page_url = link.split('->')[0]
page_title = link.split('->')[1].strip()
print(page_url, page_title)
get_pages(page_url, f"{page_title}.html")
篇幅问题,以上展示部分代码,详细代码已经放到github中 有需要的可以下载下来试试看了!
4.获取html博文执行结果
获取主页及分页面html保存到本地并将本地页面中

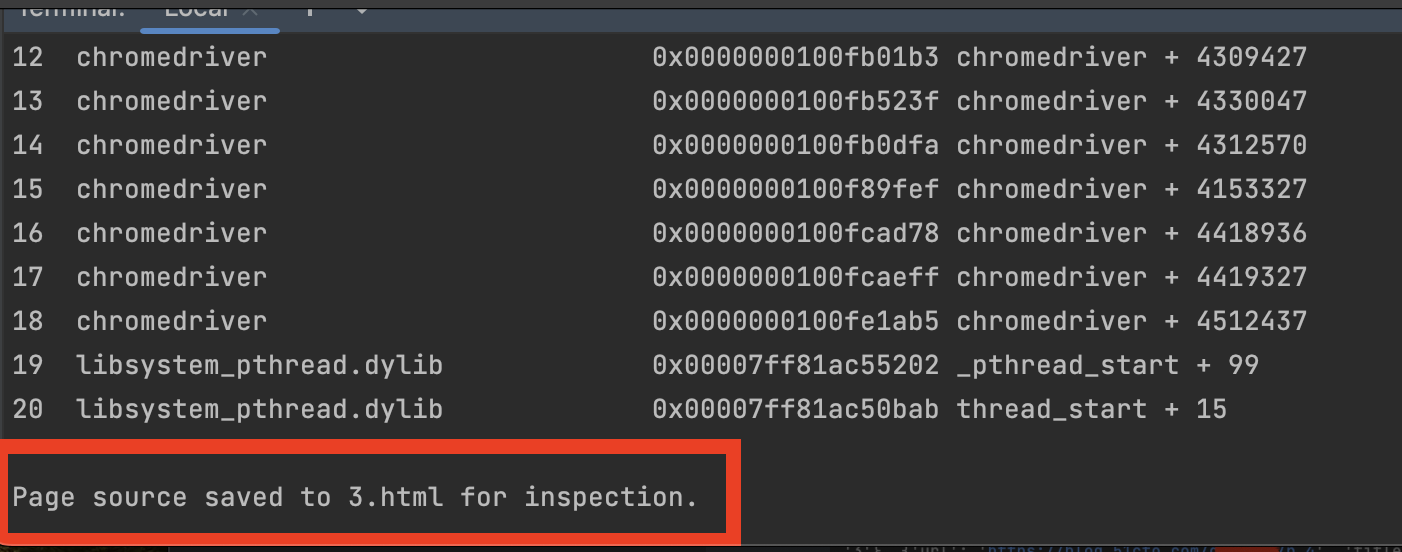
保存分页面中博文的url和标题到PageUrls.txt文件中
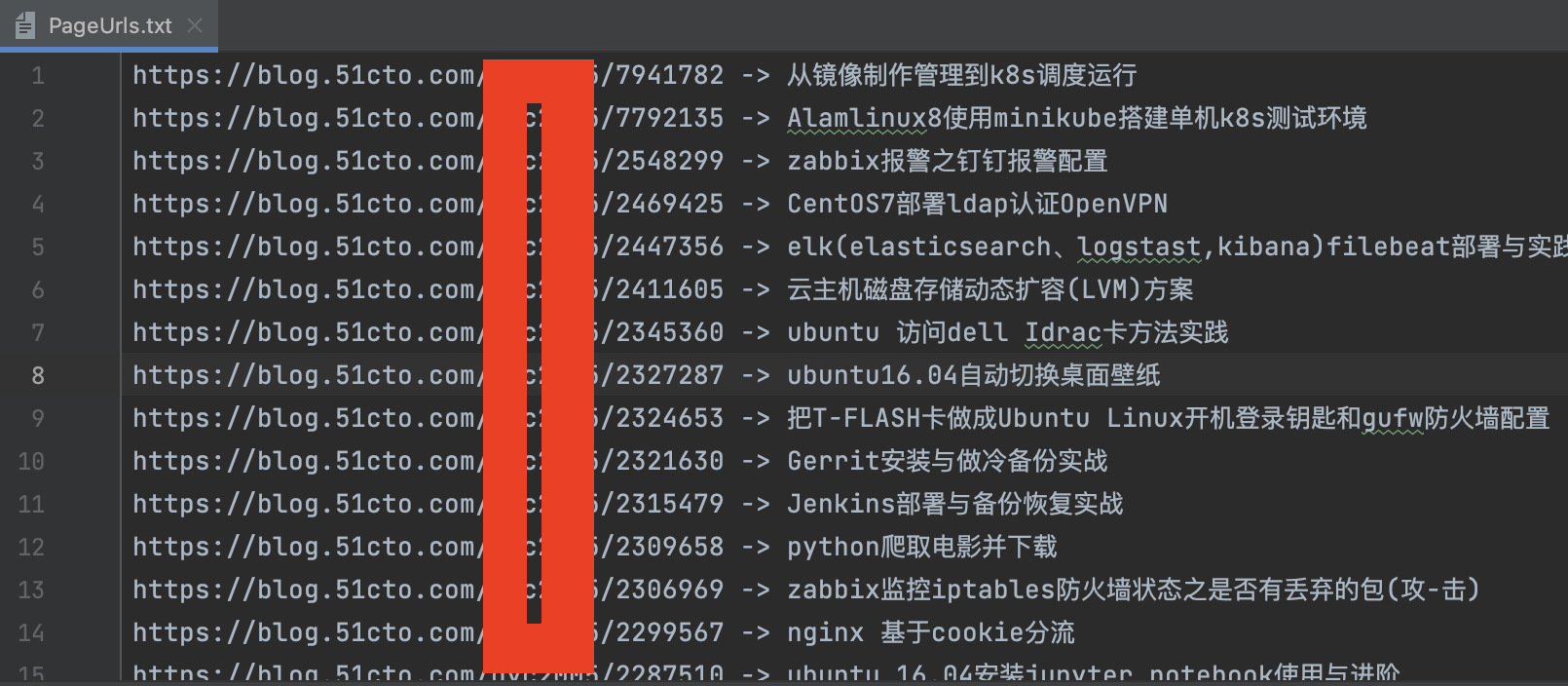
通过PageUrls.txt中的文件,下载博文以标题为名的html文件保存
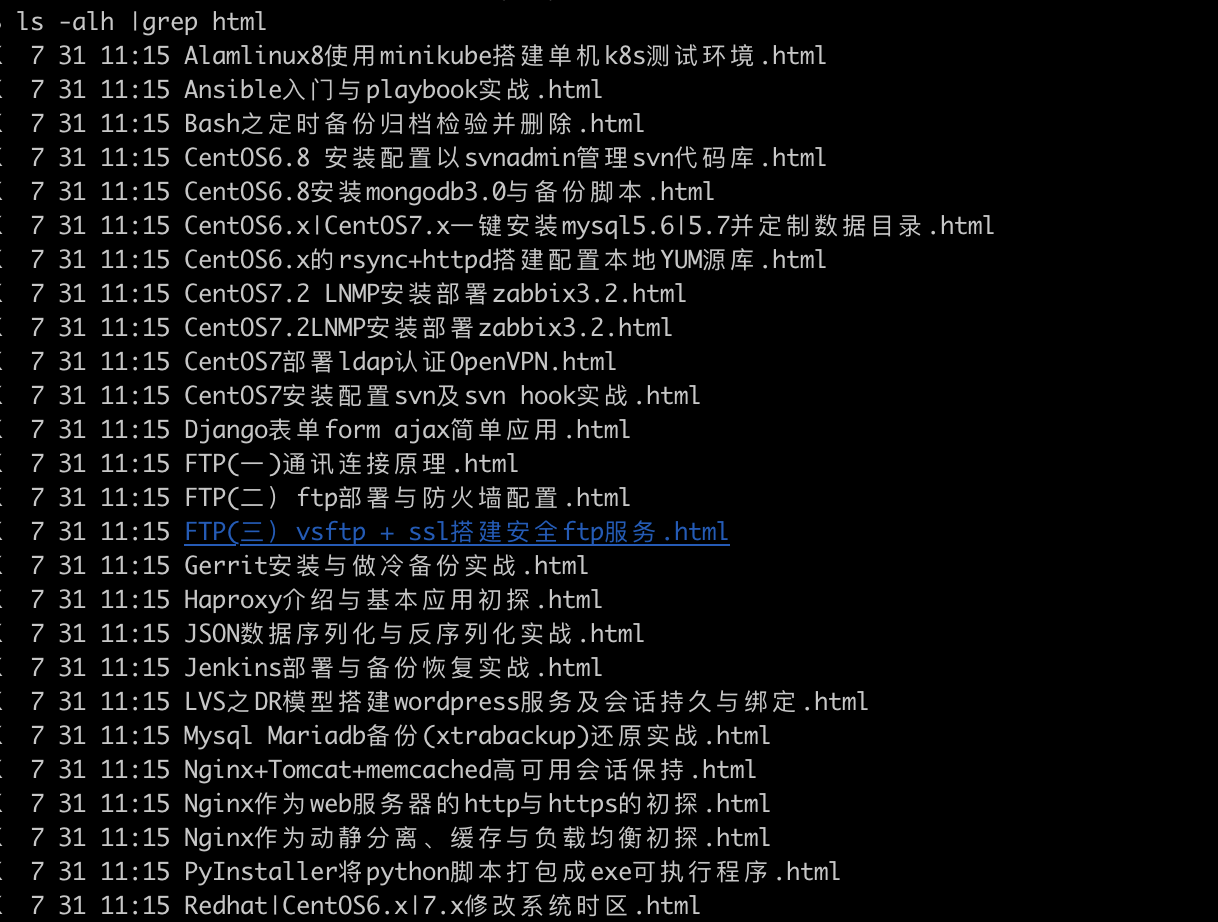
5.将本地html转成markdown
代码如下:cat htmltomd.py
from bs4 import BeautifulSoup
from markdownify import markdownify as md
import os
import requests
# 切换到目标目录
os.chdir('blogs')
# 默认的Markdown文件头部内容
default_context = '''
---
layout: post
title:
categories: [51cto老博文]
description:
keywords:
mermaid: false
sequence: false
flow: false
mathjax: false
mindmap: false
mindmap2: false
---
'''
# 下载url中的图片保存
def download_file(url, save_path):
# 发送HTTP GET请求下载文件
response = requests.get(url, stream=True)
# 确保请求成功
if response.status_code == 200:
# 打开本地文件进行写入
with open(save_path, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print(f"文件已保存到: {save_path}")
else:
print(f"无法下载文件,状态码: {response.status_code}")
...... 部分代码省略 ......
# 转换为Markdown
markdown_content = custom_md(soup, title)
# 追加Markdown内容到Markdown文件
with open(md_file_name, 'a', encoding='utf-8') as md_file:
md_file.write(markdown_content)
print(f"{f} 转换完成!")
篇幅问题,以上展示部分代码,详细代码已经放到github中 有需要的可以下载下来试试看了!
6. 后续说明
无论是下载下来本地的html文件 还是转好的markdown,都有一个问题,图片需要下载,因此以上转换文件中包含了下载原始文件(云水印),并且一并上传到github中指定目录,markdown文件中图片引用也要使用github中目录文件,这样最终完成博客从51cto到github的迁移;